Abstract: This paper describes our submission to the Second Clarity Enhancement Challenge (CEC2), which consists of target speech enhancement for hearing-aid (HA) devices, in a noisy/reverberant environment where multiple competing speakers can be present. Our approach is based on the powerful iterative neural/beamforming enhancement (iNeuBe) framework introduced in [1] plud target speaker extraction. For this reason we call our proposed approach iNeuBe-X where the "X" stands for extraction. Compared to [1] several novelties have been introduced in order to address the specific challenges encountered in the CEC2 setting. Importantly, instead of the TCNDenseNet used in [1], we devise a new, multi-channel, causal DNN adapted from a recent work [2] which alone proves to be quite effective. Other novelties regard modifications to ensure low-latency, a new speaker adaptation branch, and a fine-tuning step where we compute an additional loss with respect to a target compensated with the listener audiogram. Our best model with no external data reaches an hearing-aid speech perception index (HASPI) score of 0.942% and a scale invariant signal-to-distortion ratio improvement (SI-SDRi) of 18.83 dB on the development set. This seems remarkable given the fact that the CEC2 data is extremely challenging: e.g on the development set the mixture SI-SDR is -12.78 dB. A demo of our submitted system is available in this page.
Contents:
Some Examples from CEC2 Development Set
References
Some Examples from CEC2 Development Set
S06008S06026
S06012
S06008
|
Input Mixture (CH1 left)
|
|
System with No External Data: DNN1 output (no compensation)
|
|
System with No External Data: DNN2 output (no compensation)
|
|
System with No External Data: DNN2 output (with compensation)
|
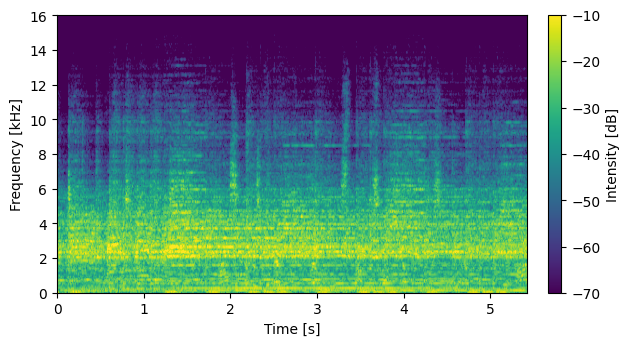
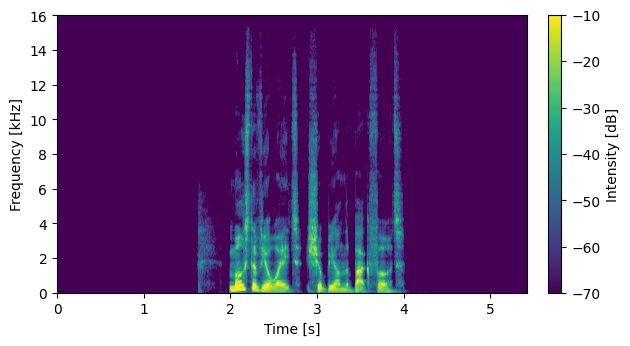
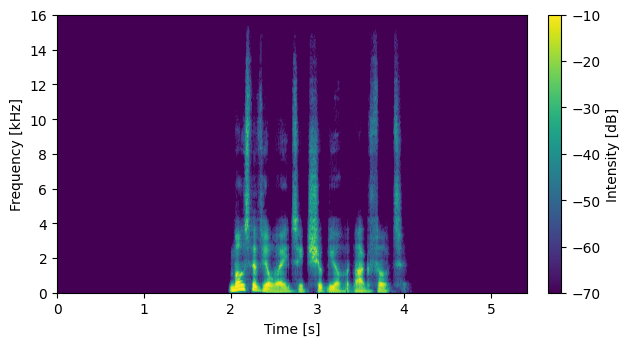
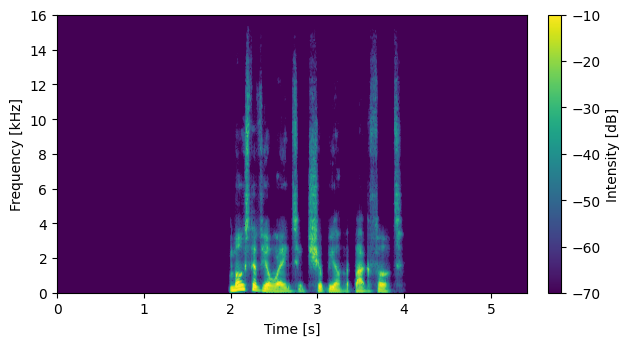
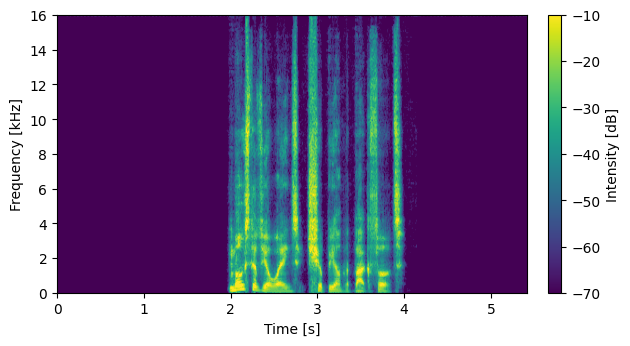
S06026
|
Input Mixture (CH1 left)
|
|
System with No External Data: DNN1 output (no compensation)
|
|
System with No External Data: DNN2 output (no compensation)
|
|
System with No External Data: DNN2 output (with compensation)
|
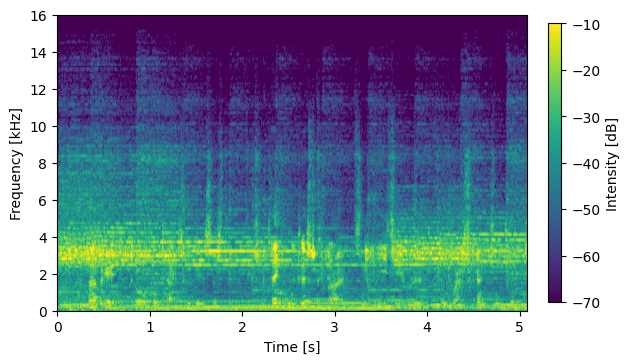
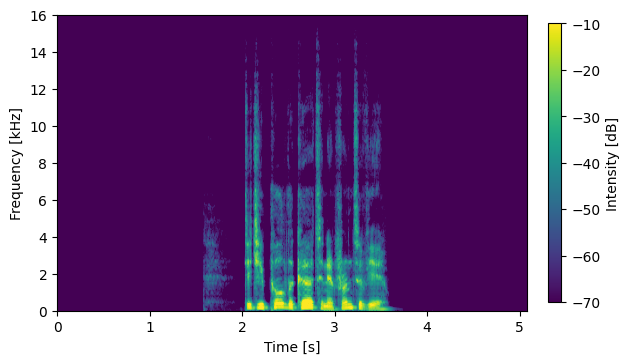
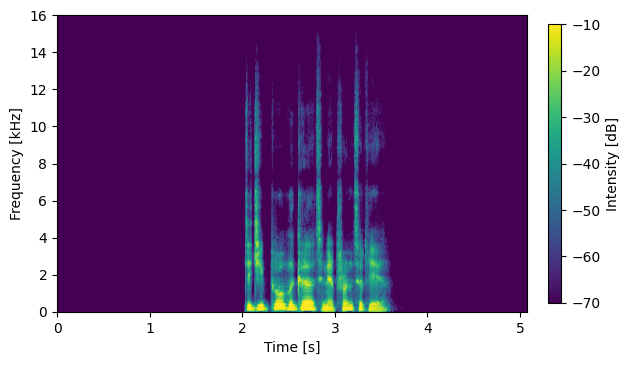
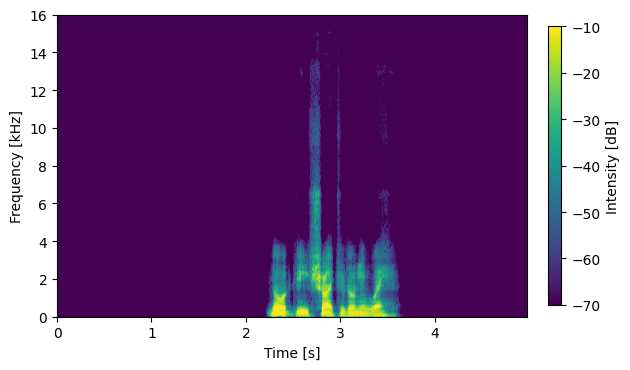
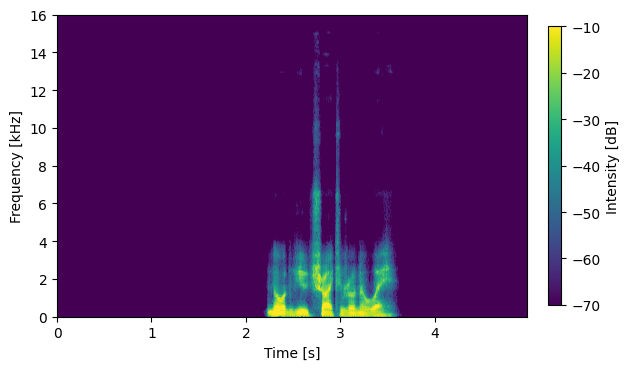
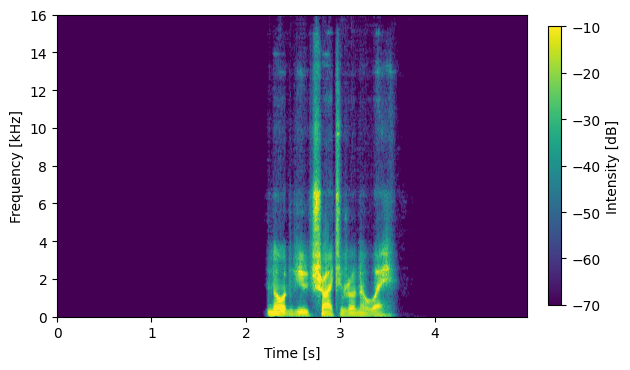
S06012
|
Input Mixture (CH1 left)
|
|
System with No External Data: DNN1 output (no compensation)
|
|
System with No External Data: DNN2 output (no compensation)
|
|
System with No External Data: DNN2 output (with compensation)
|
References:
[1] Lu, Yen-Ju, et al. "Towards Low-Distortion Multi-Channel Speech Enhancement: The ESPNET-Se Submission to the L3DAS22 Challenge." ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022. [paper]
[2] Wang, Zhong Qiu et al. "TF-MPDNN: Time-Frequency Domain Multi-Path Deep Neural Network for Monaural Anechoic Speaker Separation." In Preparation. 2022 [paper]